Big Data Notes
Exploring big data technologies with Raspberry Pi.
Hive
Theory
Overview
Hive is a data warehousing system that can be used to analyse big data using a SQL interface.
SQL commands entered by the user are translated into jobs of the underlying execution engine. For example, when using MapReduce the SQL queries are translated into MapReduce jobs. Other available engines include Spark and Tez. I’ll assume MapReduce is the engine, but the same concepts apply for the others.
It’s a powerful system for a number of reasons:
- You don’t have to learn a programming language to run MapReduce jobs.
- Hive abstracts many common operations e.g. joins.
- You can cleanly manage big data in relational tables (assuming the data is structured).
Metastore
Hive table data is stored in hdfs. The metadata for these tables (their schema etc.) is stored in a separate database - the metastore. Supported metastore databases include:
- MySQL
- PostgreSQL
- Oracle
- Derby
There are two layers to the metastore - the metastore service (referred to as metastore in the images below) and the metastore stroage layer (the green db in the images below). There are a few ways these are deployed:
- Embedded metastore: Both the database and the service are run inside the Hive service JVM:
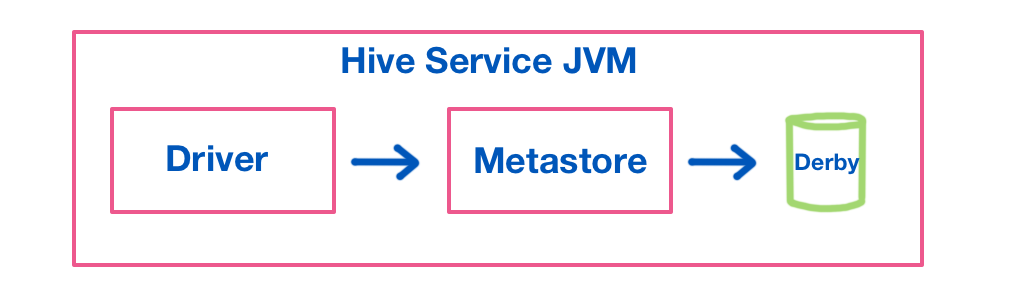 This is the default deployment mode, which runs an embedded Derby database. It’s suitable only for testing purposes - only one hive session can be active at a time as the embedded db doesn’t support concurrency.
This is the default deployment mode, which runs an embedded Derby database. It’s suitable only for testing purposes - only one hive session can be active at a time as the embedded db doesn’t support concurrency. - Local metastore: The metastore service still runs inside the Hive JVM, but the database is separate:
 Now multiple Hive sessions can be active.
Now multiple Hive sessions can be active. - Remote metastore: The metastore service is separated from the Hive JVM:
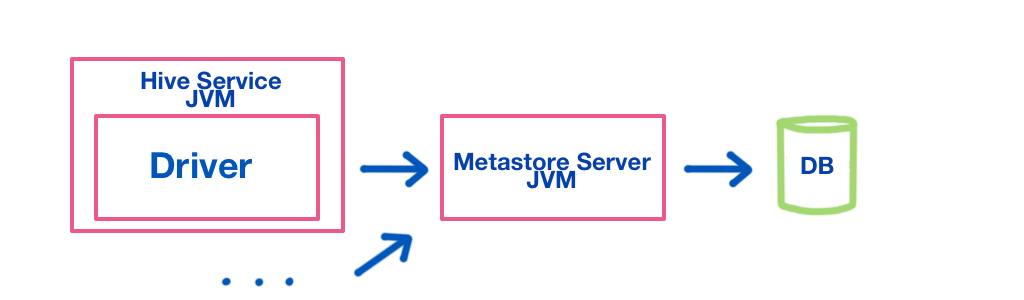 This is easier to manage for a number of reasons. For example, the database layer can be firewalled off from the Hive JVM, the Hive JVM no longer needs database credentials etc.
This is easier to manage for a number of reasons. For example, the database layer can be firewalled off from the Hive JVM, the Hive JVM no longer needs database credentials etc.
Hive Architecture
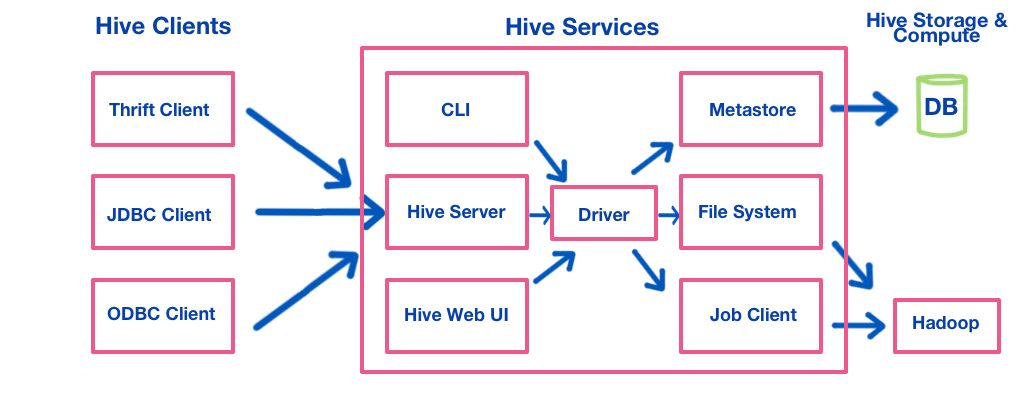 Some points on the image:
Some points on the image:
- Hive runs a server to give a range of clients access. You can use Hive CLI to execute Hive SQL commands, but because Hive CLI accesses the driver directly it needs to be run on the same machine as the driver.
- Hive clients include Thrift, JDBC and ODBC clients. An example of a JDBC client is beeline.
Partitions
Hive tables can be partitioned to make queries more efficient by only analysing slices of the dataset rather than the whole thing. For example, consider a simple weather dataset:
dt,location,temperature
20200101,Sydney,40
20200101,Munich,-5
20200101,New York,0
20200102,Sydney,33
20200102,Munich,-4
20200102,New York,-2
If this table was in an unpartitioned table weather, its file structure of the Hive tables on HDFS would be:
├── weather │ ├── 000000_0
However, if this were partitioned on the dt column the file structure would be:
├── weather │ ├── dt=20200101 │ │ └── 000000_0 │ ├── dt=20200102 │ │ └── 000000_0
And the file contents:
- dt=20200101/000000_0:
Sydney,40 Munich,-5 New York,0 - dt=20200102/000000_0:
Sydney,33 Munich,-4 New York,-2
Notice that the files don’t contain the partition columns - these are maintained in the directory structure.
To see how the above file structure makes queries more efficient consider SELECT location FROM weather WHERE dt='20200101'. To answer this, only the files in the dt=20200101 folder need to be searched.
Buckets
Buckets allow you to divide your tables/partitions into a fixed number of, well, buckets 🙂
For example say we wanted to split the weather dataset in the previous section into two buckets on the location column. The file structure would then be:
├── weather │ ├── dt=20200101 │ │ └── 000000_0 │ │ └── 000001_0 │ ├── dt=20200102 │ │ └── 000000_0 │ │ └── 000001_0
Hive computes the data’s bucket by applying
hash(BUCKET_COL) % NUM_BUCKETS
Note you can use bucketing without partitioning, in which case you’d have:
├── weather │ ├── 000000_0 │ ├── 000001_0
There are a few reasons to use buckets:
- Same benefits as partitioning i.e. queries conditional on the bucket column don’t have to scan all the data.
- If you partition on a column with high cardinality (lots of possible values), it can create too many directories with small files. HDFS isn’t optimised for this. With bucketing the number of pieces the data is sliced into is fixed.
- Less data skew when using bucketing - there should be roughly the same amount of data in each bucket.
- Sampling data is easier with bucketed tables.
Hive vs Relational DB
Remember, Hive is not a relational database. It stores the underlying data on HDFS. It’s optimised for analysing huge amounts of structured data, not for low latency sql selects and updates.
Another difference worth keeping in mind is that Hive is schema on read, not schema on write.
Cluster Examples
Installation
- Download the Hive binary tarball. This can be done with the command
curl -O http://binary_tarball_url. The url can be found on the releases page - Unpack the tarball and move it:
sudo tar xzvf apache-hive-x.y.z-bin.tar.gz -C /opt cd /opt sudo mv apache-hive-x.y.z-bin hive - Set up environment variables:
export HIVE_HOME=/opt/hive export PATH=$PATH:$HIVE_HOME/bin - Go to Hive config directory:
cd $HIVE_HOME/conf - Setup Hive configurations as shown in this video. It should open up at 5:02.
Examples
Creating Tables
Start the cli by typing hive. Now let’s play around with a table:
create table people(FirstName String, LastName String, NickName String);
insert into people values("Billy", "Smith", "Big b");
select * from people;
You can see how the data is stored in hdfs:
hadoop fs -ls /user/hive/warehouse/people
hadoop fs -cat /user/hive/warehouse/people/000000_0
If you were to insert more data into the table, it would create a new file under people.
You can also create tables from HDFS files. First put a csv files with the data on HDFS:
echo "Billy,Smith,Big B\nBobby,Tanner,T bob\nSally,Sinatra,Sal" > people.csv
hadoop fs -mkdir people
hadoop fs -copyFromLocal people.csv people
Now in the Hive shell create the table from this csv file:
DROP TABLE people;
CREATE EXTERNAL TABLE people(FirstName String, LastName String, NickName String)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/<user>/people';
Just replace <user> in the above command with your HDFS user.
Note the usage of EXTERNAL TABLE. This indicates that the data will be accessed by applications other than Hive. You can see the data isn’t stored at /user/hive/warehouse as it was in the original example. It’s at the location we specified - /user/<user>/people.
If we issue a DROP TABLE on an external table, only the metadata will be deleted. If it’s a managed table, both the data and the metadata is deleted.
Creating Partitions
There are two types of partitions in Hive - static and dynamic.
For static partitions, the partition that data should be in is explicitly specified when it is loaded into the table. This is more efficient as Hive doesn’t have to figure out what partition the data should sit in, as is the case with dynamic partitions.
To illustrate the difference, let’s run through an example with a small weather dataset. First copy the dataset to HDFS:
echo "20200101,Sydney,40\n20200101,Munich,-5\n20200101,New York,0\n20200102,Sydney,33\n20200102,Munich,-4\n20200102,New York,-2" > weather.csv
hadoop -fs mkdir weather
hadoop fs -copyFromLocal weather.csv weather
Now start up Hive and create a table to hold the data:
CREATE EXTERNAL TABLE weather (dt String, location String, temperature STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/<user>/weather';
Setup a table which is the same as weather, but is partitioned on the date column:
CREATE TABLE weather_partitioned (location String, temperature STRING)
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
To insert data from the unpartitioned weather table into the partitioned weather table using static partitioning, the partition of the data being inserted is specified in the statement:
INSERT INTO TABLE weather_partitioned
PARTITION (dt='20200101')
SELECT location, temperature FROM weather
WHERE dt='20200101';
Using dynamic partitioning we don’t have to specify the partition of the data being inserted:
set hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO weather_partitioned
PARTITION (dt)
SELECT location, temperature, dt FROM weather;
Creating buckets
The CLUSTERED BY statement is used to create buckets.
Let’s create a bucketed table and insert the weather data from the previous section into it:
CREATE TABLE weather_bucketed (location String, temperature STRING)
PARTITIONED BY (dt STRING)
CLUSTERED BY (location) INTO 2 BUCKETS
set hive.enforce.bucketing = true;
INSERT INTO weather_bucketed
PARTITION (dt)
SELECT location, temperature, dt FROM weather;
Of course, with a real dataset we’d have a lot more than three locations and so would create more buckets.